AI Foundation
 January 26, 2026
January 26, 2026AI #
A selection of notes that didn’t fit elsewhere or are being worked on!.
Home
January 26, 2026A selection of notes that didn’t fit elsewhere or are being worked on!.
July 4, 2024Artificial Intelligence is often described in three stages, based on capability and scope:
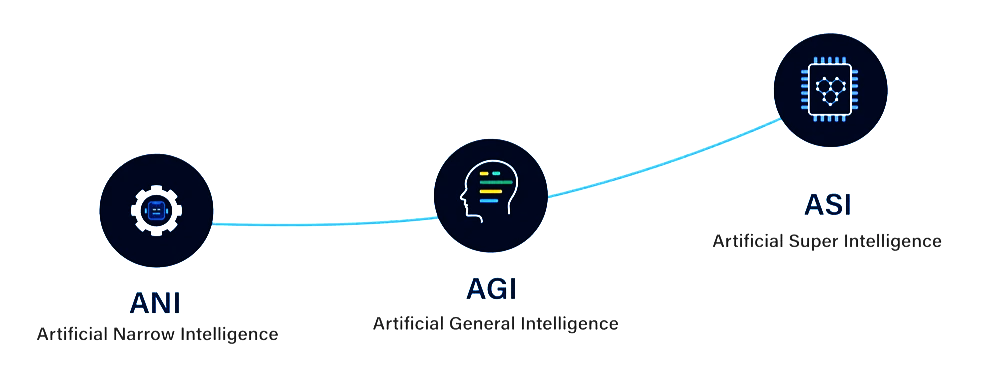
examples
Statistics: describes data (what you see).
Probability: models uncertainty (what you don’t know yet).
flowchart TD
A[Dataset] --> B[Central Tendency]
A --> C[Variability]
B --> B1[Mean]
B --> B2[Median]
B --> B3[Mode]
C --> C1[Range]
C --> C2[Variance]
C --> C3[Standard Deviation]
C --> C4[IQR]
Central tendency tells you where the “middle” of the data is. Describes a set of scores with a single number that describes the PERFORMANCE of the group.
Probability models uncertainty: what you don’t know yet, but want to reason about.
Key takeaway: Probability is a number between 0 and 1 that measures how likely an event is. The whole topic is about defining events clearly and applying a few core rules consistently.
Probability quantifies uncertainty: a number between 0 and 1.
A random experiment is an action whose outcome is not known in advance.
flowchart LR
subgraph subGraph0["Input Layer"]
I1(("Input 1"))
I2(("Input 2"))
I3(("Input 3"))
end
subgraph subGraph1["Hidden Layer"]
H1(("Hidden 1"))
H2(("Hidden 2"))
H3(("Hidden 3"))
end
subgraph subGraph2["Output Layer"]
O(("Output"))
end
I1 --> H1 & H2 & H3
I2 --> H1 & H2 & H3
I3 --> H1 & H2 & H3
H1 --> O
H2 --> O
H3 --> O
style I1 fill:#C8E6C9
style I2 fill:#C8E6C9
style I3 fill:#C8E6C9
style H1 stroke:#2962FF,fill:#BBDEFB
style H2 fill:#BBDEFB
style H3 fill:#BBDEFB
style O fill:#FFCDD2
style subGraph0 stroke:none,fill:transparent
style subGraph1 stroke:none,fill:transparent
style subGraph2 stroke:none,fill:transparent
A typical neural network has three main layers:
March 12, 2026Probability often changes when we learn new information.
Conditional probability and Bayes’ theorem give a structured way to update beliefs using evidence.
Conditional probability updates probabilities after observing an event.
Bayes’ theorem lets you estimate a hidden cause from observed evidence.
Naïve Bayes turns Bayes’ theorem into a practical classifier by assuming conditional independence of features given the class.
flowchart TD A[Conditional<br/>probability] -->|foundation| B[Bayes<br/>theorem] D[Independent<br/>events] -->|implies| C[Independence] C -->|simplifies| A E[Prior] -->|with likelihood| B F[Likelihood] -->|updates| H[Posterior] G[Evidence] -->|normalises| B B -->|yields| H I[Naïve<br/>Bayes] -->|uses| B J[Naïve<br/>assumption] -->|assumes| C K[Features] -->|given class| J L[Class] -->|conditions| J I -->|predicts| M[Classification] M -->|selects| L style A fill:#90CAF9,stroke:#1E88E5,color:#000 style B fill:#90CAF9,stroke:#1E88E5,color:#000 style C fill:#90CAF9,stroke:#1E88E5,color:#000 style D fill:#CE93D8,stroke:#8E24AA,color:#000 style E fill:#CE93D8,stroke:#8E24AA,color:#000 style F fill:#CE93D8,stroke:#8E24AA,color:#000 style G fill:#CE93D8,stroke:#8E24AA,color:#000 style J fill:#CE93D8,stroke:#8E24AA,color:#000 style K fill:#CE93D8,stroke:#8E24AA,color:#000 style L fill:#CE93D8,stroke:#8E24AA,color:#000 style H fill:#C8E6C9,stroke:#2E7D32,color:#000 style I fill:#C8E6C9,stroke:#2E7D32,color:#000 style M fill:#C8E6C9,stroke:#2E7D32,color:#000
Probability Distributions
Move from events to random variables and distributions.
August 6, 2024
stateDiagram-v2
%% ===== CLASS DEFINITIONS (Math-based colours) =====
classDef algebra fill:#cfe8ff,stroke:#1e3a8a,stroke-width:1px
classDef probability fill:#d1fae5,stroke:#065f46,stroke-width:1px
classDef geometry fill:#ffedd5,stroke:#9a3412,stroke-width:1px
classDef logic fill:#ede9fe,stroke:#5b21b6,stroke-width:1px
classDef category font-style:italic,font-weight:bold,fill:#aaaaaa,stroke:#374151,stroke-width:3px
%% ===== ROOT =====
ML: Machine Learning
%% ===== SUPERVISED =====
ML --> SL:::category
SL: Supervised Learning
SL --> Regression
Regression --> LR:::algebra
LR: Linear Regression
LR --> NN:::algebra
NN: Neural Network
NN --> DT:::logic
DT: Decision Tree
SL --> Classification
Classification --> NB:::probability
NB: Naive Bayes
NB --> KNN:::geometry
KNN: k-Nearest Neighbours
KNN --> SVM:::algebra
SVM: Support Vector Machine
%% ===== UNSUPERVISED =====
ML --> USL:::category
USL: Unsupervised Learning
USL --> Clustering
Clustering --> KM:::geometry
KM: K-Means
KM --> GMM:::probability
GMM: Gaussian Mixture Model
GMM --> HMM:::probability
HMM: Hidden Markov Model
%% ===== REINFORCEMENT =====
ML --> RL:::category
RL: Reinforcement Learning
RL --> DM:::logic
DM: Decision Making
Used heavily when models rely on:
The AI Stack describes the layers required to build an end-to-end AI system, from infrastructure at the bottom to user-facing applications at the top.
Different organisations represent the AI stack differently; this is a simplified conceptual view for learning.
Each layer depends on the one below it.
graph TB
subgraph APP["Applications"]
A[User Interfaces & Integrations]
end
subgraph ORCH["Orchestration"]
O[Workflows • Agents • Control Logic]
end
subgraph DATA["Data"]
D[Data Sources • Pipelines • Vector DBs]
end
subgraph MODEL["Models"]
M[ML • DL • Foundation Models • LLMs]
end
subgraph INFRA["Infrastructure"]
I[Cloud • On-prem • GPUs • Storage]
end
%% Styling
style APP fill:#FFCCBC
style ORCH fill:#90CAF9
style DATA fill:#BBDEFB
style MODEL fill:#C8E6C9
style INFRA fill:#E1F5FE
style A fill:#FFE0B2
style O fill:#B3E5FC
style D fill:#E3F2FD
style M fill:#DCEDC8
style I fill:#E1F5FE
The foundation that provides compute and storage.
knowledge in neural networks is stored in connection weights, and learning means modifying those weights.
A biological neuron is a specialised cell that processes and transmits information through electrical and chemical signals.
Core components:
Biological intuition:
An artificial neuron is a simplified computational model inspired by biological neurons.
Data is the foundation of any machine learning system. Quality of data matters more than model complexity.
Data determines:
Bad data → bad model (even with perfect algorithms).
Raw data is never ready for training.
Data Issues
Data Preprocessing techniques