Trained using labelled data. Each example in the training set includes the correct output. The algorithm learns to generalise and make predictions on unseen data. Generally more accurate than unsupervised methods. Requires human intervention for labelling and setup. Widely used due to its accuracy and efficiency. Produces highly accurate results when trained on good-quality labelled data.
Output is discrete (e.g. Yes/No, Spam/Not Spam). Used for categorising data into predefined classes. Support Vector Machine (SVM) is a common classifier (a linear classifier with margin-based separation).
Learning how machines learn! My working notes as I learn AI.
flowchart LR
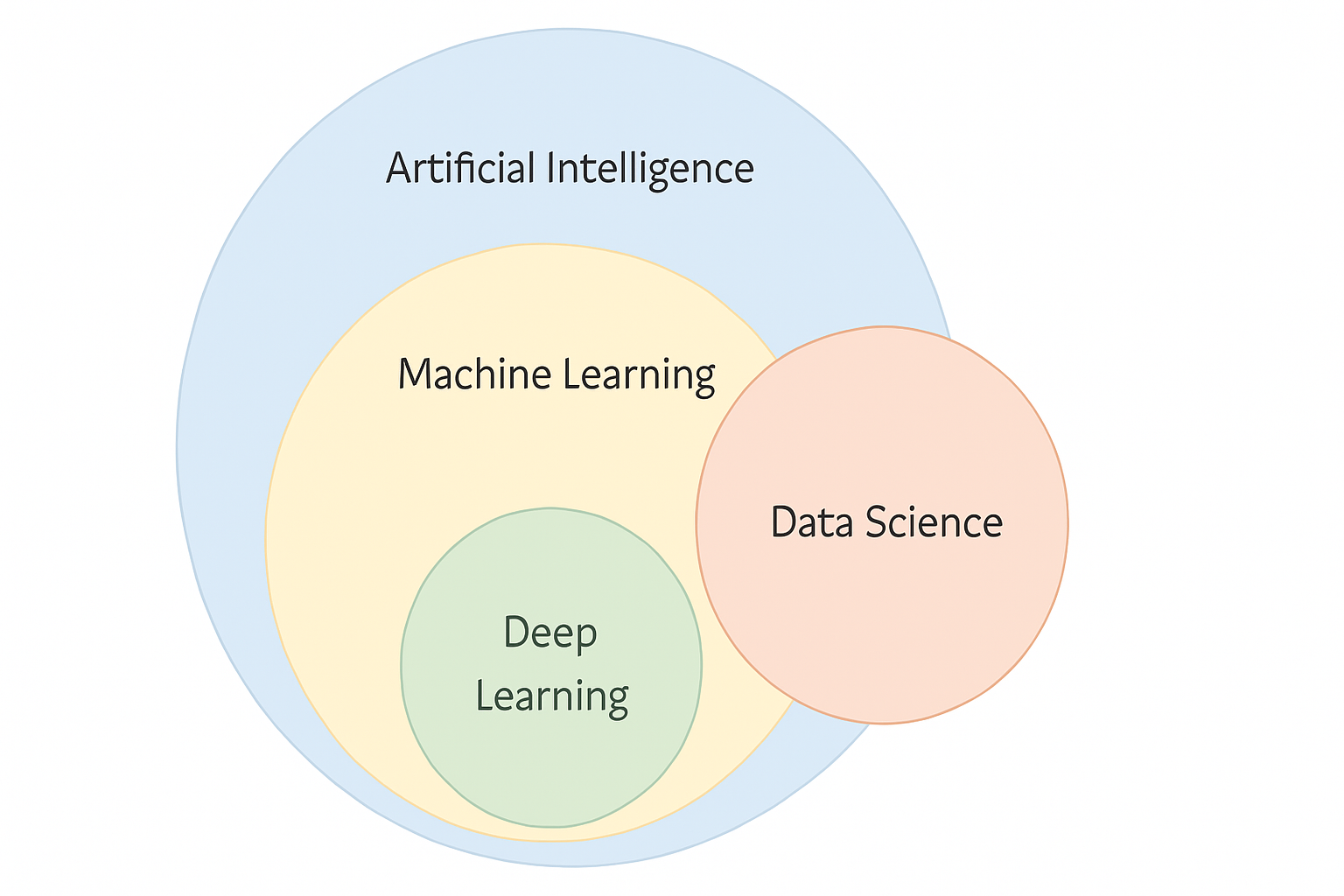
AI[Artificial Intelligence]
ML[Machine Learning]
DL[Deep Learning]
FM[Foundation Models]
LLM[LLM Models]
AI --> ML
ML --> DL
DL --> FM
FM --> LLM
style AI fill:#E1F5FE
style ML fill:#C8E6C9
style DL fill:#90CAF9
style FM fill:#64B5F6
style LLM fill:#FFCCBC
Statistics: describes data (what you see). Probability: models uncertainty (what you don’t know yet).
Summarise a dataset using central tendency and variability
Explain core probability ideas using simple examples
Apply the axioms of probability
Distinguish mutually exclusive vs independent events
flowchart TD
A[Dataset] --> B[Central Tendency]
A --> C[Variability]
B --> B1[Mean]
B --> B2[Median]
B --> B3[Mode]
C --> C1[Range]
C --> C2[Variance]
C --> C3[Standard Deviation]
C --> C4[IQR]
Central tendency tells you where the “middle” of the data is.
Describes a set of scores with a single number that describes the PERFORMANCE of the group.
Probability models uncertainty:
what you don’t know yet, but want to reason about.
Key takeaway:
Probability is a number between 0 and 1 that measures how likely an event is.
The whole topic is about defining events clearly and applying a few core rules consistently.
Probability quantifies uncertainty: a number between 0 and 1.
 March 12, 2026
March 12, 2026