Machine Learning is built on mathematical principles that allow models to:
represent data
learn patterns
optimise performance
flowchart LR
DATA[Data]
MATH[Math Models]
OPT[Optimisation]
MODEL[Trained Model]
DATA --> MATH
MATH --> OPT
OPT --> MODEL
ML requires core mathematical tools to understand how ML algorithms work internally. Algebra deals with relationships between variables and quantities, while Calculus focuses on change and optimization.
performing a specific operation (like addition or multiplication) on members of a set always produces a result that belongs to the same set
idea of closure is fundamental to defining a Vector space because it ensures that performing arithmetic operations (addition and scalar multiplication) on vectors within a set does not produce a new element outside that set.
the mathematical framework for understanding and controlling how quantities change
the mathematics of change and accumulation
It helps answer:
How fast is something changing right now?
What happens when inputs change slightly?
Where is something maximum or minimum?
It answers two big questions:
How fast is something changing right now? → derivatives (differentiation)
How much has accumulated over an interval? → integrals (integration)
flowchart TD
A[Calculus] --> B[Limits]
B --> C[Continuity]
B --> D[Derivatives]
B --> E[Integrals]
D --> F[Optimisation: maxima/minima]
D --> G[ML: gradients & learning]
E --> H[Accumulation: area/total change]
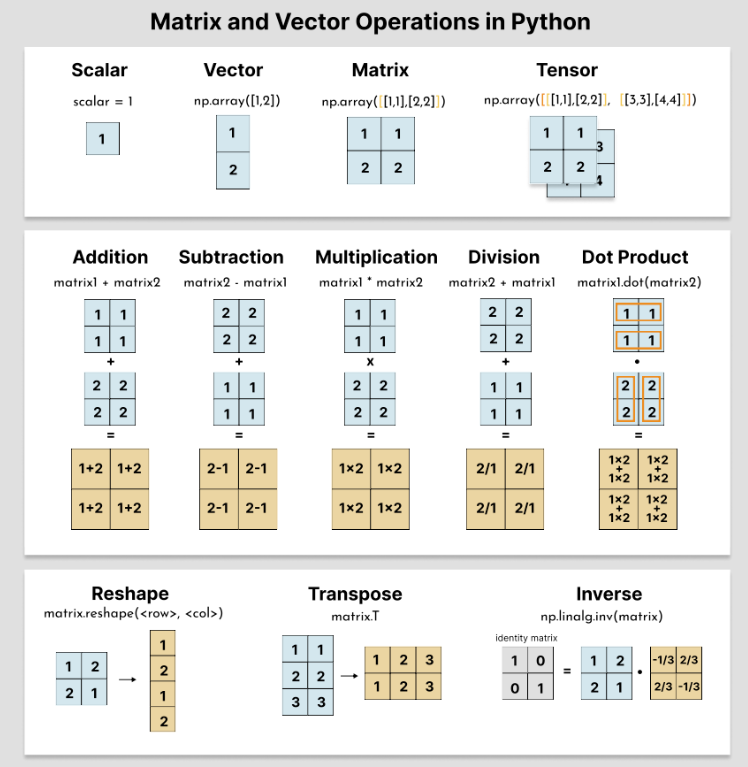
Matrices are the core data structure of linear algebra and the workhorse of machine learning. Almost every ML model can be described as a sequence of matrix operations.
A square matrix is positive definite if pre-multiplying and post-multiplying it by the same vector always gives a positive number as a result, independently of how we choose the vector.
Positive definite symmetric matrices have the property that all their eigenvalues are positive.
 May 28, 2026
May 28, 2026